Dynamic Filtering: Let the Model Program Its Own Search Filters
Anthropic’s Programmatic Tool Calling (PTC) lets models write code to control web search and filter results before they enter context, improving efficiency but remaining locked to a closed API. By extracting the core idea, dynamic filtering, and rebuilding it with the Tavily CLI as an open skill, the same pattern can run in any coding agent using Bash and Python.


Anthropic recently shipped Programmatic Tool Calling (PTC), where Claude writes Python code that orchestrates web search inside a cloud sandbox, filtering results before they enter context. On their benchmarks, it improved accuracy by 11% and cut token usage by 24%. It’s a powerful idea - but locked to the Anthropic API and a cloud sandbox you can’t inspect.
We broke down the pattern, extracted the general principle, and rebuilt it as an open alternative using the Tavily CLI and a skill - a single markdown file that teaches any coding agent to do dynamic filtering with Bash and Python.
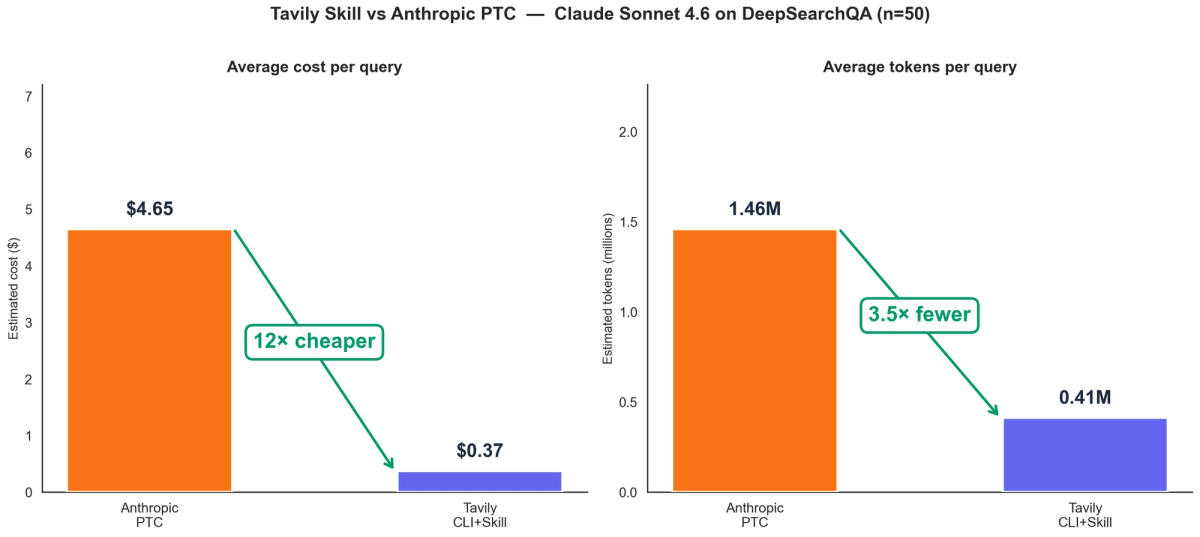
We tested on the same DeepSearchQA benchmark that Anthropic used. On the full 900-question set with Claude Sonnet 4.6, our skill-based approach scores 72.7% F1 - compared to Anthropic’s reported 59.4% with dynamic filtering. In a head-to-head comparison on a 50-question subset, the skill approach is ~12× cheaper and uses ~3.5× fewer tokens than PTC.
Results: DeepSearchQA benchmark
DeepSearchQA is a benchmark of 900 research-style questions where each answer contains multiple items that must all be found via web search. It tests whether an agent can systematically plan and execute multi-step searches without missing any answers.
How F1 is calculated
DeepSearchQA questions have multi-part answers - for example, “List all U.S. states that meet criteria X and Y.” Following the benchmark’s evaluation methodology, each answer is treated as a set of items where order doesn’t matter. An LLM judge compares the model’s answer against the reference by checking which items were found correctly, which were missed, and which were hallucinated:
- Precision: what fraction of the model’s answers are actually correct?
- Recall: what fraction of the reference answers were found?
- F1: the harmonic mean of both, balancing accuracy and completeness
For example, if the reference answer is “California, Texas, Florida, New York” and the model answers “California, Texas, Ohio”:
- Correct (✅): California, Texas (2 of 3 submitted)
- Missed (❌): Florida, New York (2 of 4 reference items not found)
- Hallucinated (⚠️): Ohio (1 incorrect item)
From these, we compute:
- Precision = 2 correct / 3 submitted = 0.67
- Recall = 2 found / 4 reference items = 0.50
- F1 = 2 × 0.67 × 0.50 / (0.67 + 0.50) = 0.57
This penalizes both incomplete answers and hallucinations - an agent can’t game the score by guessing broadly.
Each question’s F1 is computed individually, then averaged over all questions in the dataset to get the overall F1 score.
Full benchmark (N=900): Skills vs Anthropic-reported numbers
We ran the skill-based approach on all 900 DeepSearchQA questions using Claude Sonnet 4.6, the same model and benchmark Anthropic evaluated.
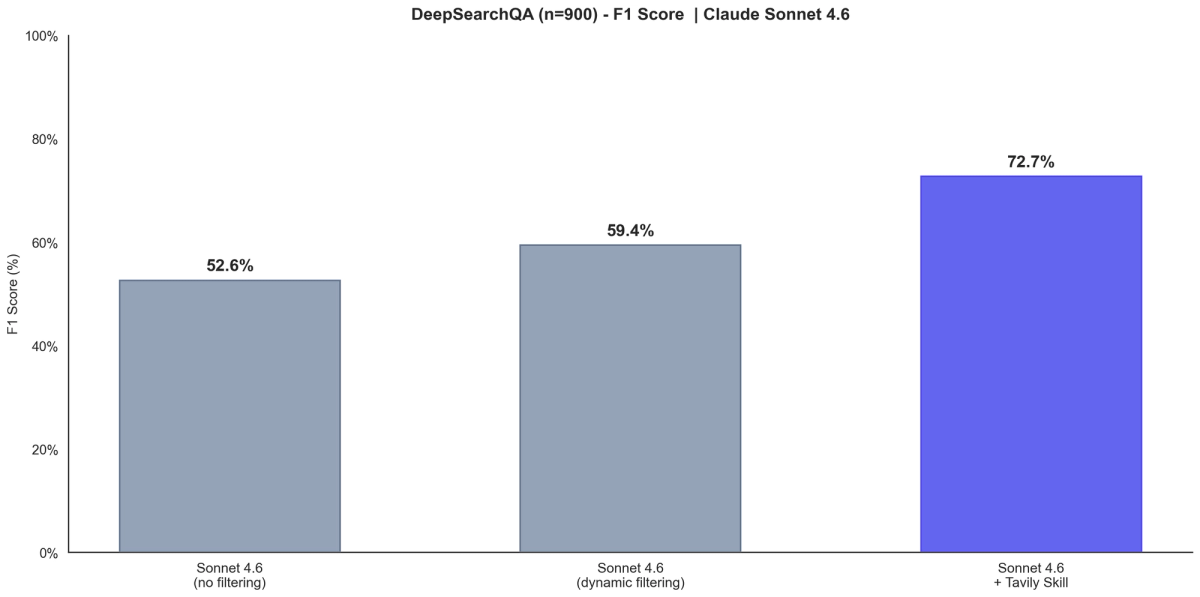
The skill approach scores 72.7% F1 — 13 points above Anthropic’s Sonnet 4.6 with dynamic filtering (59.4%) on the same model, same benchmark dataset, and the same evaluator methodology (item-level F1 scoring).
Head-to-head (N=50): Skills vs API
To directly compare the two approaches, we ran both the skill-based approach and PTC on the same 50-question subset of DeepSearchQA, with a 600-second timeout per question. Both used claude-sonnet-4.6 as the model.
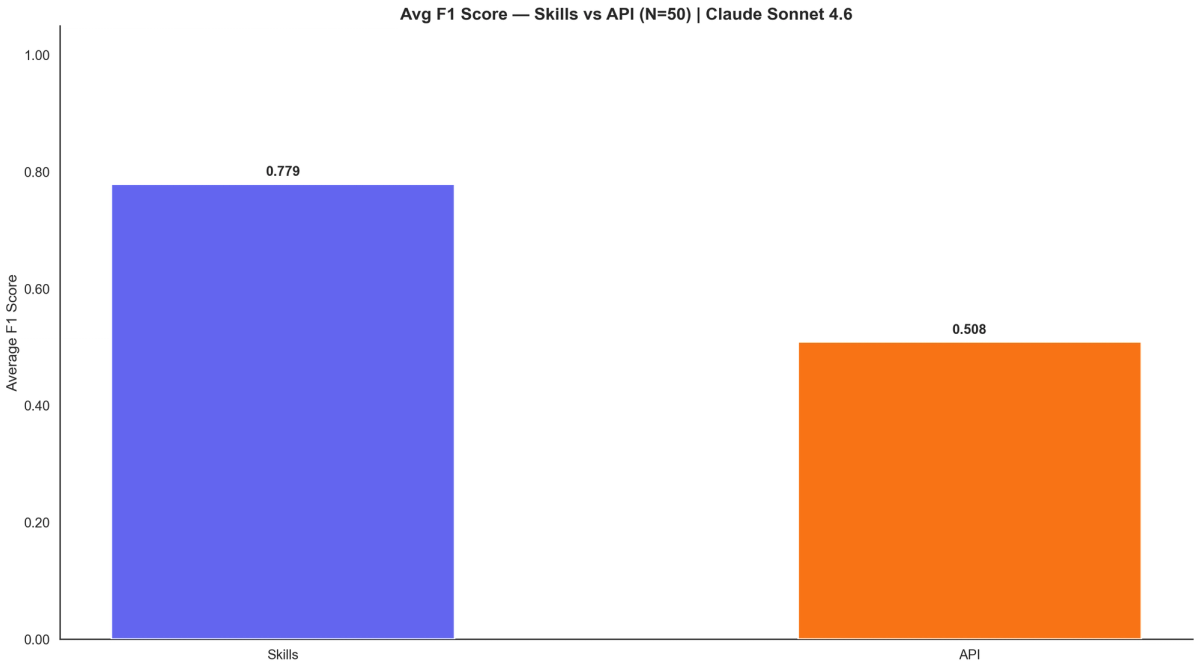
The skill-based approach achieved 77.9% F1 versus 50.8% F1 for PTC - a 53% relative improvement.
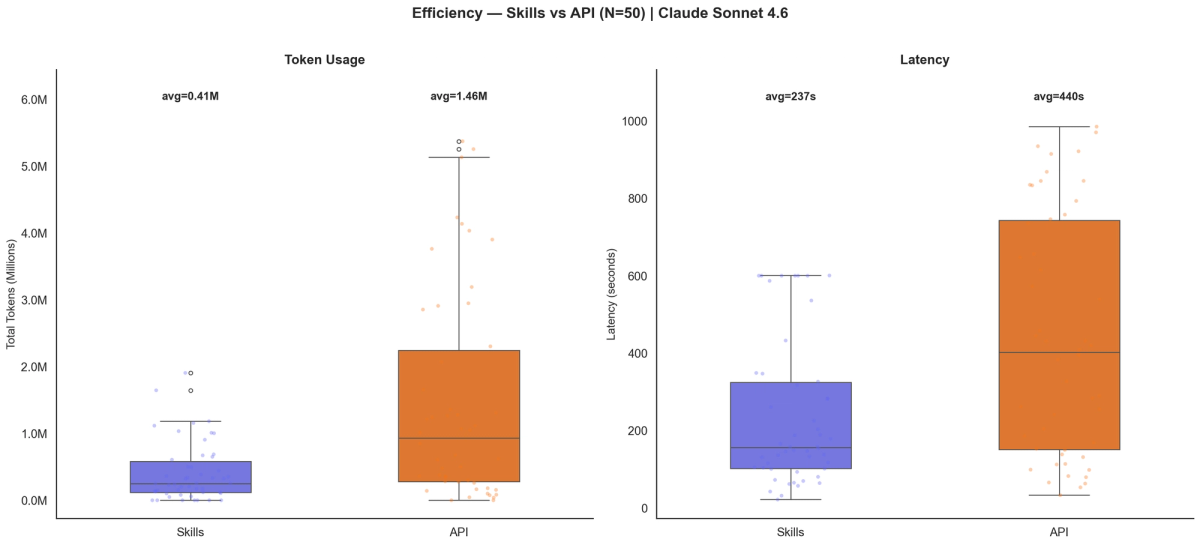
The efficiency gap is stark. The skill approach averages 413K tokens per query at $0.37/query, while PTC averages 1.46M tokens at $4.65/query — roughly 3.5× fewer tokens and 12× cheaper.
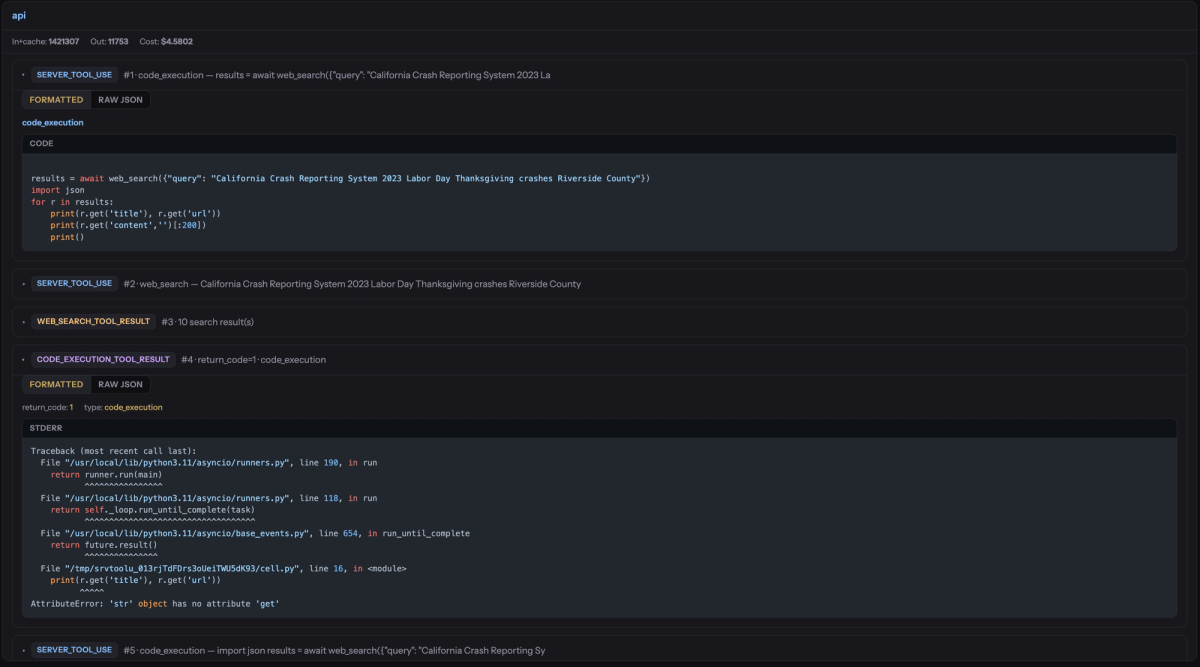
A cursory look at the traces showed that the PTC / cloud sandbox approach ran into repeated failures due to syntax errors and other issues, possibly due to inconsistent handling of the search results.
What Anthropic built
Anthropic introduced dynamic filtering as part of PTC. As their team puts it: instead of making tool calls that each round-trip through the model’s context, the model writes code that orchestrates tool calls directly. Intermediate results return to the code, not the context window.
Three server-side tools compose to make this work:
- code_execution - Claude writes and runs Python in a cloud sandbox
- web_search - callable from within that Python code, not as a separate top-level tool call
- web_fetch - also callable from within the sandbox
Because search and fetch are nested under code execution, raw results stay inside the sandbox’s memory. The model’s own Python code decides what’s worth keeping, and only the print() output crosses back into context - a “narrow gate” between raw data and the model’s reasoning.
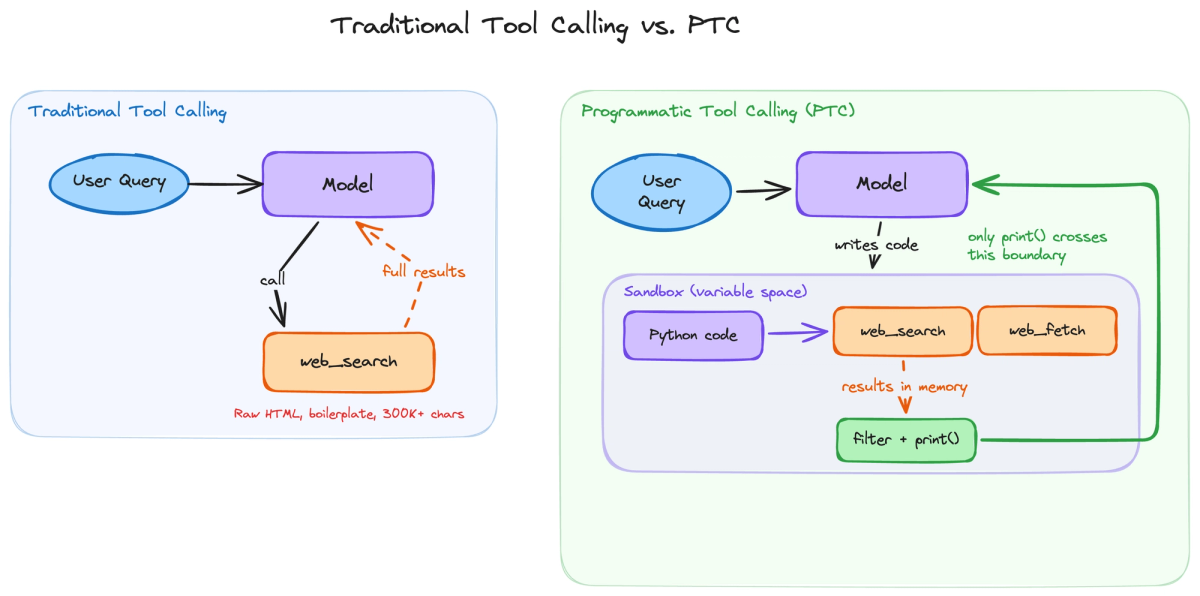
The model also self-corrects: when a code cell fails, it sees the traceback and writes a corrected cell, iterating entirely within the sandbox.
It’s a real advance, but it comes with constraints. PTC works only at the Anthropic API level and operates in a cloud sandbox you can’t inspect or extend.
How dynamic filtering works
Strip away the Anthropic-specific implementation and the pattern is straightforward. The model writes a program that does the searching, reading, and filtering - and only the program’s output enters the model’s context.
1. The model writes a search-and-filter program. Before any search happens, the model writes a program based on the query and the tool schema. It doesn’t need to know the winning pages in advance - just a first-pass strategy for what to look for and how to triage. An SEC filing question gets code that parses financial tables; a product comparison question gets code that extracts specifications into a structured table.
2. Search results stay in the execution environment. The program runs: results come back as variables in a sandbox (PTC) or data flowing through a pipe (skill approach). Raw page content stays in the execution environment, never in the model’s context.
3. The program surfaces only what matters. Only print() output crosses back into context - a few hundred tokens of headers, extracted fields, or computed values rather than tens of thousands of tokens of raw HTML.
4. The model may iterate. Based on the lightweight results, the model can write new code - fetch a specific page, drill into a table, chase a cross-reference - filtering again before surfacing.
The critical insight is that the filters aren’t keyword lists or regex patterns. They’re arbitrary program logic the model writes fresh for each query: score thresholds, field selection, deduplication, JSON parsing, table extraction, numeric computation, URL heuristics. The model is programming a bespoke pipeline at runtime. This is Sutton’s bitter lesson applied to search: general methods that leverage computation beat hand-engineered solutions.
Any system that gives the model code execution, web access from within that code, and an output boundary (only stdout returns to context) can implement this pattern. Every modern coding agent already has Bash and Python; the missing piece is a search tool that speaks the terminal’s language. The Tavily CLI (tvly) fills that gap.
Why this matters
Portable harness capabilities
There’s a useful frame for thinking about coding agents: model + harness. The harness is everything but the model - orchestration, tools, skills - and it shapes what the model can do. Viv Trivedy, Mitchell Hashimoto, HumanLayer, and LangChain have all written about this idea.
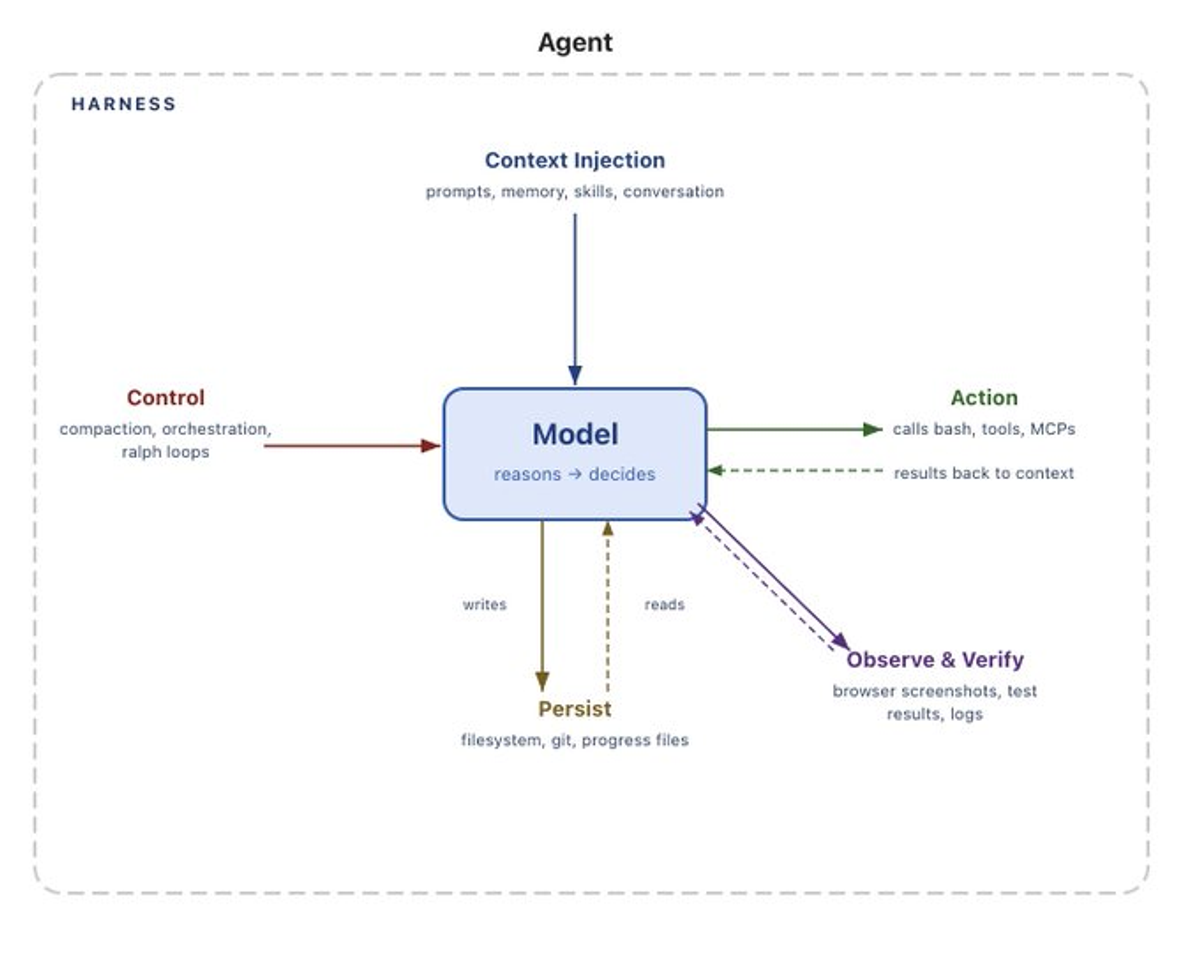
PTC is a harness-level capability built into the Anthropic API. It requires specific tool type identifiers (web_search_20260209) and Anthropic’s cloud sandbox - powerful but non-portable.
The Tavily CLI + Skill takes a different approach: a markdown file that teaches any model in any harness the dynamic filtering pattern. It doesn’t add tools; it teaches the model to use tools it already has (bash) in a specific way. It works in Claude Code, Codex, Cursor, pi - any harness with terminal access.
HumanLayer found that harness configuration dramatically affects performance - the same model jumps from #33 to #5 on TerminalBench 2.0 just by changing the harness. A skill gives you that configurability portably.
Keeping context lean
The model has access to two spaces: variable space (data in the execution environment - Python variables, files, pipe buffers) and token space (the model’s context window). Variable space is cheap to store and free to ignore. Token space is expensive, and degrades reasoning as it grows.
Dynamic filtering keeps the variable space large and the token space lean. The model writes code to selectively pull what it needs from one to the other - what Zhang and Khattab formalize as Recursive Language Models. They showed that this lets a smaller model outperform a larger one on long-context benchmarks, because no single call ever sees the full context. PTC and the skill approach both follow this architecture - the difference is where the execution environment lives.
Replicating it with the Tavily CLI
We built a skill called tavily-dynamic-search - a single markdown file that teaches any coding agent this pattern. It documents the tvly JSON schemas so the model writes correct Python, and enforces one core rule: always pipe search output through a filtering script so raw results never enter context.
Here’s what the model actually generates - a bash pipeline it wrote because the query is about battery companies, so it knows to look for production and partnership mentions:
tvly search "solid-state battery companies 2026" --include-raw-content markdown --json \\
| python3 -c "
import json, sys
data = json.load(sys.stdin)
for r in data.get('results', []):
if r.get('score', 0) > 0.7:
content = r.get('raw_content', '')
# Model-written filter: keep only paragraphs about production/partnerships
lines = [l for l in content.split('\\n') if any(
kw in l.lower() for kw in ['production', 'factory', 'partner']
)]
if lines:
print(f\\"## {r['title']}\\")
print(f\\"URL: {r['url']}\\")
print('\\n'.join(lines[:5]))
print()
"The full page content flows through the pipe but never enters the model’s context. Only the print() output - the filtered excerpts - returns. A different query would produce entirely different filtering logic.
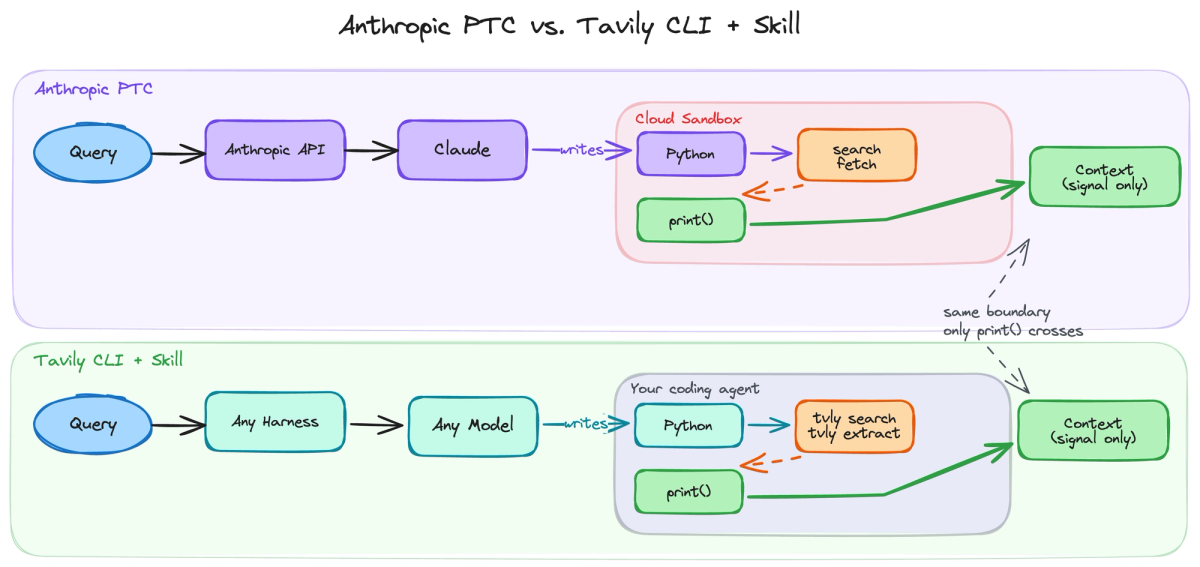
The skill documents JSON schemas for tvly search and tvly extract, teaches two execution modes (pipe for simple lookups, heredoc for multi-step logic), and enforces the core rule of piping through Python. We encourage the model to save intermediate results to /tmp/ for multi-turn iteration, with a more hardened approach under development for future releases.
Get started
- Install the Tavily CLI:
curl -fsSL https://cli.tavily.com/install.sh | bash- Authenticate: `tvly auth` with your Tavily API key or OAuth (opens browser)
- Add the skill:
npx skills add https://github.com/tavily-ai/skills- Use it: The skill activates automatically when the agent needs to search. It will compose `tvly` commands with Python filtering instead of dumping raw results into context.
The skill works with Claude Code, Codex, Cursor, pi, and any other agent harness that provides bash access. No new infrastructure or dependencies beyond tvly.
Demo video
Further reading
- Tavily CLI: Web access for AI agents
- Anthropic: Improved web search with dynamic filtering
- Anthropic: Advanced tool use - Programmatic Tool Calling
- Alex Zhang & Omar Khattab: Recursive Language Models
- Rich Sutton: The Bitter Lesson
- Viv Trivedy: The Claude Code SDK and HaaS
- LangChain: The Anatomy of an Agent Harness
- HumanLayer: Skill Issue - Harness Engineering for Coding Agents